

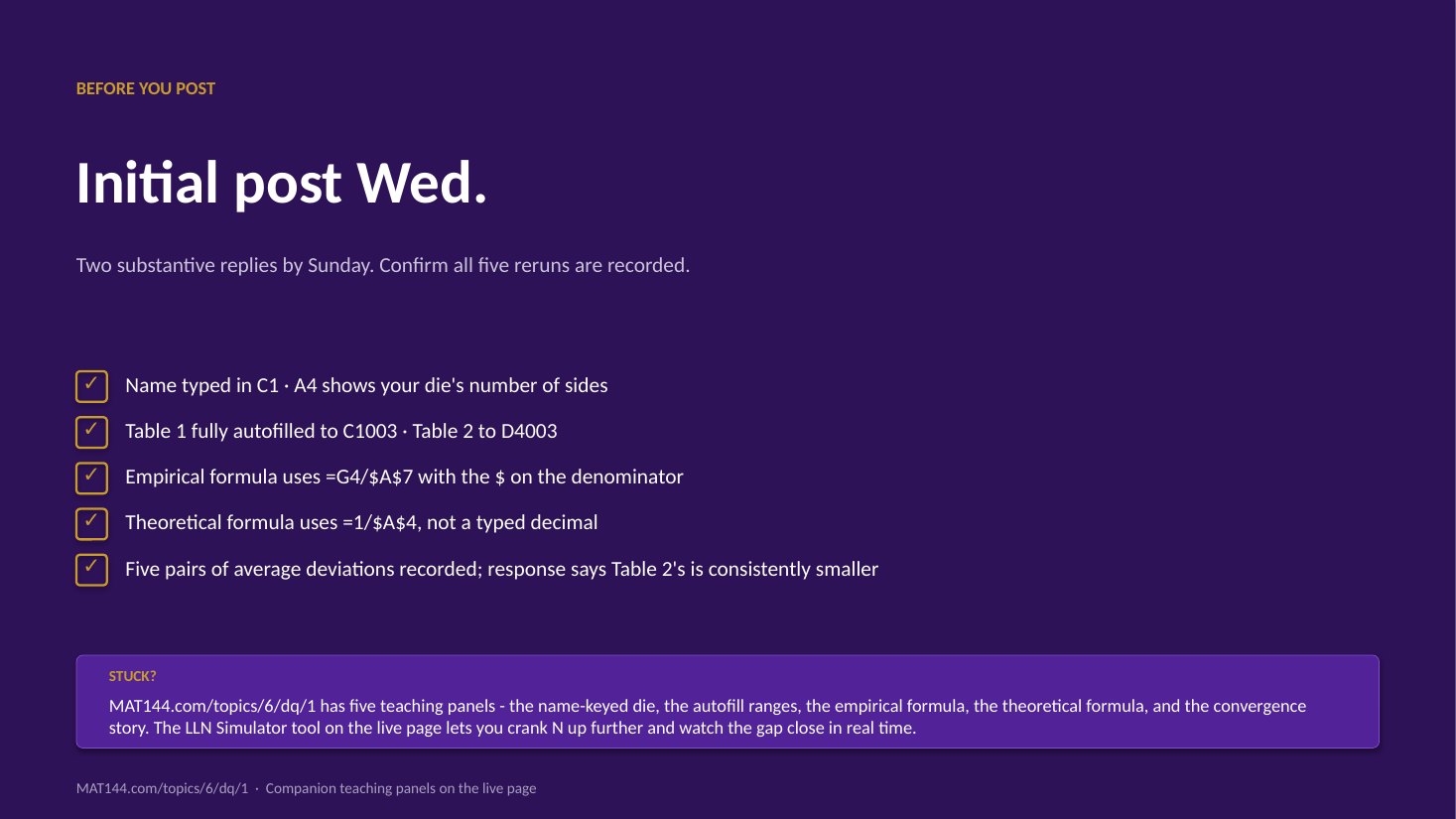
The die
Name-keyed, 10 to 15 sides.
The die has between 10 and 15 sides, and
the exact number is set by a formula in cell A4
that depends on your name: =MOD(LEN(C1)*5857,6)+10.
Two students with the same name length get the same die; a
different name produces a different die. Until you type
your name in C1, the rest of the sheet sits
blank.
The roll itself is generated by Excel's
=RANDBETWEEN(1, $A$4) in cells
C4 and D4. Each time you trigger
a recalculation (the easiest way: type any character in
the "Response" cell K30 and press
Enter), every RANDBETWEEN in the sheet
re-rolls. Think of it as rolling the die fresh every time
the sheet recalculates.